Implementation¶
别的不说了,提一嘴流水线处理
支持复杂的流水线时隙处理 (Pipelined slot processing):
现实中的商用PHY(如FlexRAN和srsRAN)处理时隙的任务比理论模型更复杂,通常采用多任务流水线设计
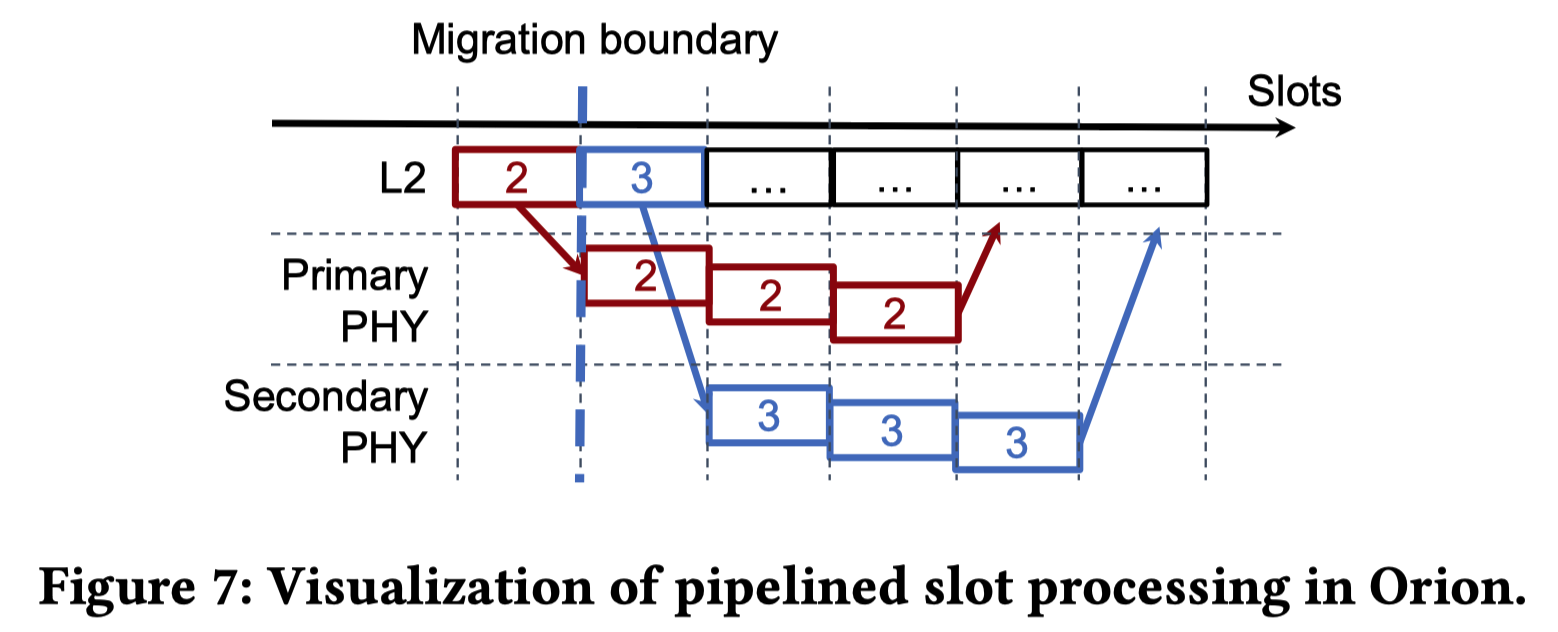
该图直观地展示了FlexRAN的三时隙上行链路处理流水线以及Orion对边界数据的处理方式
- 如果PHY迁移发生在时隙#2和#3的边界,主PHY在迁移命令下达后,依然会继续输出之前时隙#2的计算结果
- Orion会被巧妙地配置为继续接收这部分“残余”数据,从而最大程度减少丢失的TTI
这种机制使得Slingshot在处理计划内迁移时,能进一步降低用户的网络停机时间
Orion会被巧妙地配置为继续接收这部分“残余”数据
(1) bgd: PHY 的流水线处理
在理想模型中: 我们会觉得PHY在“时隙1(Slot 1)”收到数据,就会在“时隙1”内处理完并输出结果
但现实中的商业PHY软件(比如论文中使用的FlexRAN)是非常复杂的:
它处理一个时隙的数据,实际上需要经历一条跨越多个时隙的流水线
比如上图: 在时隙#2进来的原始数据,PHY要吭哧吭哧算到时隙#4,才能得出最终的解码结果
(2) 为什么要"继续接收"
假设我们现在决定在时隙#2 和 时隙#3 的交界处,把工作从“主PHY”迁移到“备用PHY”
- 对于时隙#3及以后的新数据:前传交换机会把它们发给“备用PHY”去处理。没问题
- 但是: 对于时隙#2(以及时隙#1)的数据:它们此时正卡在“主PHY”的流水线里加工到一半
如果Orion在切换的那一瞬间,就非常生硬地“拉黑”主PHY,只听备用PHY的话,那么主PHY费劲算完的时隙#2的结果就无处可去了
这部分数据就会被丢弃,这就是所谓的“丢失了TTI”
丢了数据,上层就得触发重传,用户就会感觉到网络卡顿
(3) 如何巧妙配置: "脚踏两条船"
为了避免上述浪费,Orion被设计成了可以“脚踏两只船”的过渡状态。
当在时隙#2和#3的边界发生迁移后:
- 主PHY虽然不再接收新数据,但它还会继续把流水线里没干完的活儿干完(即继续输出时隙#2的最终计算结果)
- Orion中间件被配置为:
- 对于新的时隙(#3及以后),它接收来自备用PHY的响应
- 但同时,它依然保持一条通道,继续接收主PHY吐出来的、属于过去时隙的最终结果(“残余”数据)