Reactive Migration¶
这一节详细论述了 Atlas 如何应对突发的软硬件故障(故障转移/Failover)
-
为何与主动迁移不同:
- 应对突发崩溃(如服务器死机)时,原本的 DU 已经瘫痪,无法参与原本的“切换(Handover)”协作
- 由于这类故障发生频率远低于日常维护,系统可以容忍极其短暂的断网(类似于用户日常遭遇的信号盲区)
-
核心机制:Atlas 重新利用了蜂窝网络原生的“小区重选(Cell Reselection)”机制
- 让设备迅速在备用 DU 上重新建联
基础重连流程¶
我们的理想情况:
- 系统在不同的服务器上维护着一个共享的、处于热备状态的备份 DU
- 当主 DU 崩溃时,前传网络功能(Fronthaul NF)会迅速把发生故障的无线电单元(RU)的数据流量重定向给备份 DU
- 此时,用户设备(UE)因为突然收不到原 DU 的下行信号,会触发“无线电链路失败(RLF)”超时机制
- 随后 UE 开始搜寻最佳信号,并顺理成章地连接到刚刚上线的备份 DU
实现"无缝迁移"
现存 5G 协议的致命缺陷¶
如果在现有 5G 架构下仅仅依靠上述的底层流量重定向,UE 依然会面临高达 3 秒的延迟,且最终会彻底断网
如 Figure 6 所示,由于基站故障导致的下行 TCP 吞吐量归零以及后续的超时表现
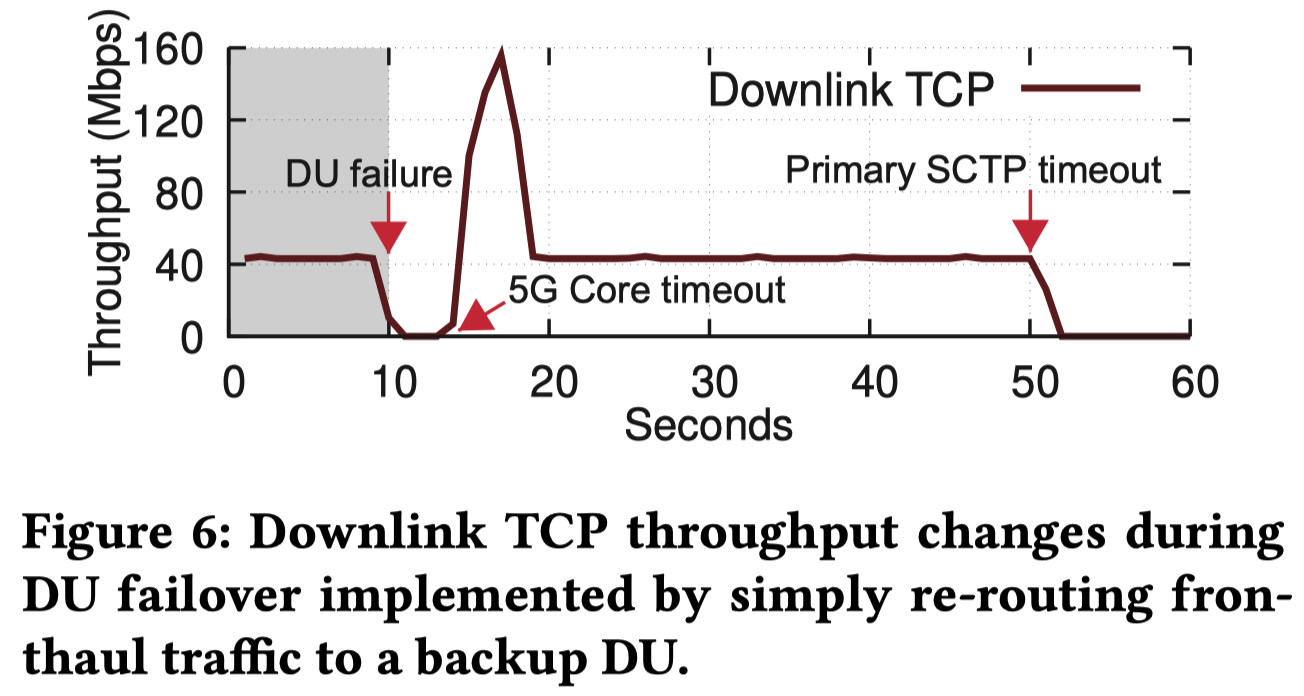
这是因为现有协议根本没有“DU 宕机”的概念:
-
缺陷一(引发 3 秒恢复延迟):
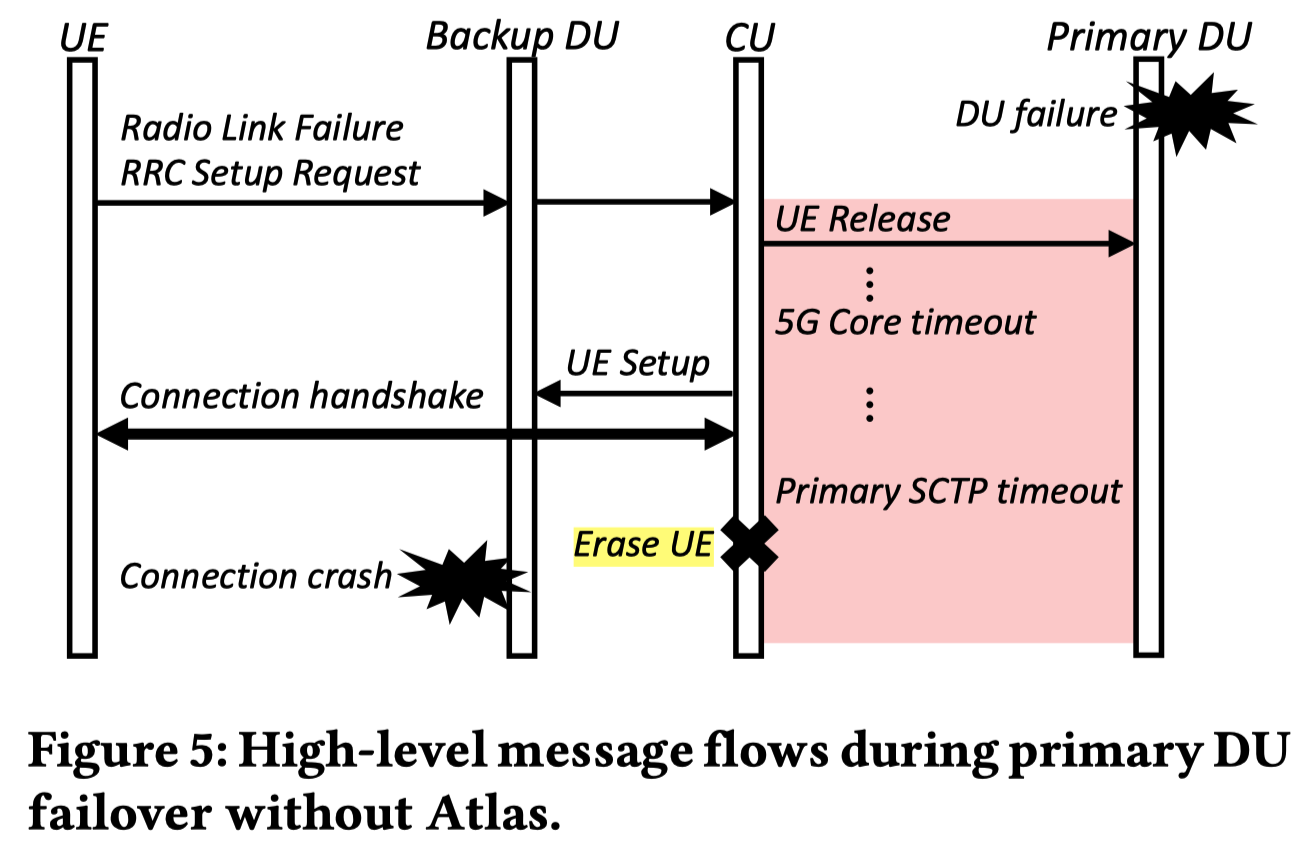
- 如 Figure 5 所示
- 上层的集中式单元(CU)并不知道底层主 DU 已经崩溃
- 当用户通过备份 DU 发起重连请求时,CU 会按常规流程要求那个已经死掉的主 DU 去“释放用户”,并在得不到回应的情况下死等
- 直到触发 5G 核心网的超时(3秒)后,才会批准用户在备用 DU 上的连接
-
缺陷二(引发彻底断网):
- 同样如 Figure 5 所示
- 崩溃约 30 秒后,CU 与死掉的主 DU 之间的底层 SCTP 连接终于因为超时而彻底断开
- 此时 CU 的默认协议处理逻辑极其粗暴: 它会直接删掉所有曾挂载在主 DU 上的用户记录
- 这会把刚才好不容易通过备用 DU 重连成功的用户强行踢下线
Atlas 的解法: 赋予网络"故障感知能力"¶
- 为了绕开协议缺陷,Atlas 引入了一个“中传网络功能(Midhaul NF)”和“故障转移管理器”
- 这个中传中间件透明地拦截了 CU 和所有 DU 之间的控制层面连接(SCTP)
- 当探测到主 DU 失去心跳(崩溃)后,中传中间件会立刻且主动地掐断主 DU 到 CU 的 SCTP 连接
- 这迫使 CU 瞬间明白主 DU 已死, 从而:
- 在用户发起重连请求之前,就干净利落地释放掉相关用户的连接状态
- 完美避开了上述的超时死等和后续的误杀逻辑
极速故障转移的时间线¶
通过上述机制,Atlas 将整个故障恢复过程压缩到了极致:
- T=0 毫秒:主 DU 崩溃宕机
- T=50 毫秒:探测到故障,前传网络重定向流量至备份 DU
- T=150 毫秒:中传网络主动掐断 SCTP 连接,向 CU 报警
- T=600 毫秒:用户设备宣告链路失败(RLF 超时),开始向备份 DU 尝试重连
- T=700 毫秒:用户设备恢复数据交换
- 整个重建过程仅需 100 毫秒(从 T=600 到 T=700),远远快于从零开始的全新连接(约 950 毫秒)
- 因为更高层(CU 和核心网)依然完好地保留着该用户的认证密钥和上下文信息