Background and Motivation¶
Motivation for RAN resilience¶
- 高可用性需求:
- 蜂窝网络是关键基础设施,电信部署通常需要“五个九(99.999%)”的运行时间,这意味着每年最多只能有6分钟的停机时间
- 当前vRAN的脆弱性:
- 目前的vRAN在处理故障或升级时,会造成严重的网络中断
- 即使立即切换,用户连接断开也会长达6.2秒
- 硬件与软件故障:
- 服务器硬件容易发生故障(平均无故障时间仅为10到60天)
- 而vRAN软件也由于Linux中支持实时应用的局限性极易崩溃
- 计划内升级的痛点:
- 网络运营商(如AT&T)可能每天都在升级其部分RAN网络,目前这需要预先计划的停机维护窗口,因此急需零停机时间的升级机制
A primer on vRAN deployments¶
(1) 硬件架构:
vRAN由无线电单元(RU)组成,通过 光纤前传链路(fronthaul) 连接到附近边缘数据中心的商用服务器
其中L1(PHY)和L2具有严格的实时延迟要求
(2) 软件复杂性:
vRAN包含由专门供应商编写的庞大且高度优化的多线程软件
PHY负责计算密集型的信号处理(如Intel FlexRAN),而L2主要负责为用户调度频率和时间资源
(3) Functional splits and interfaces:
标准的vRAN协议栈的简化结构视图:
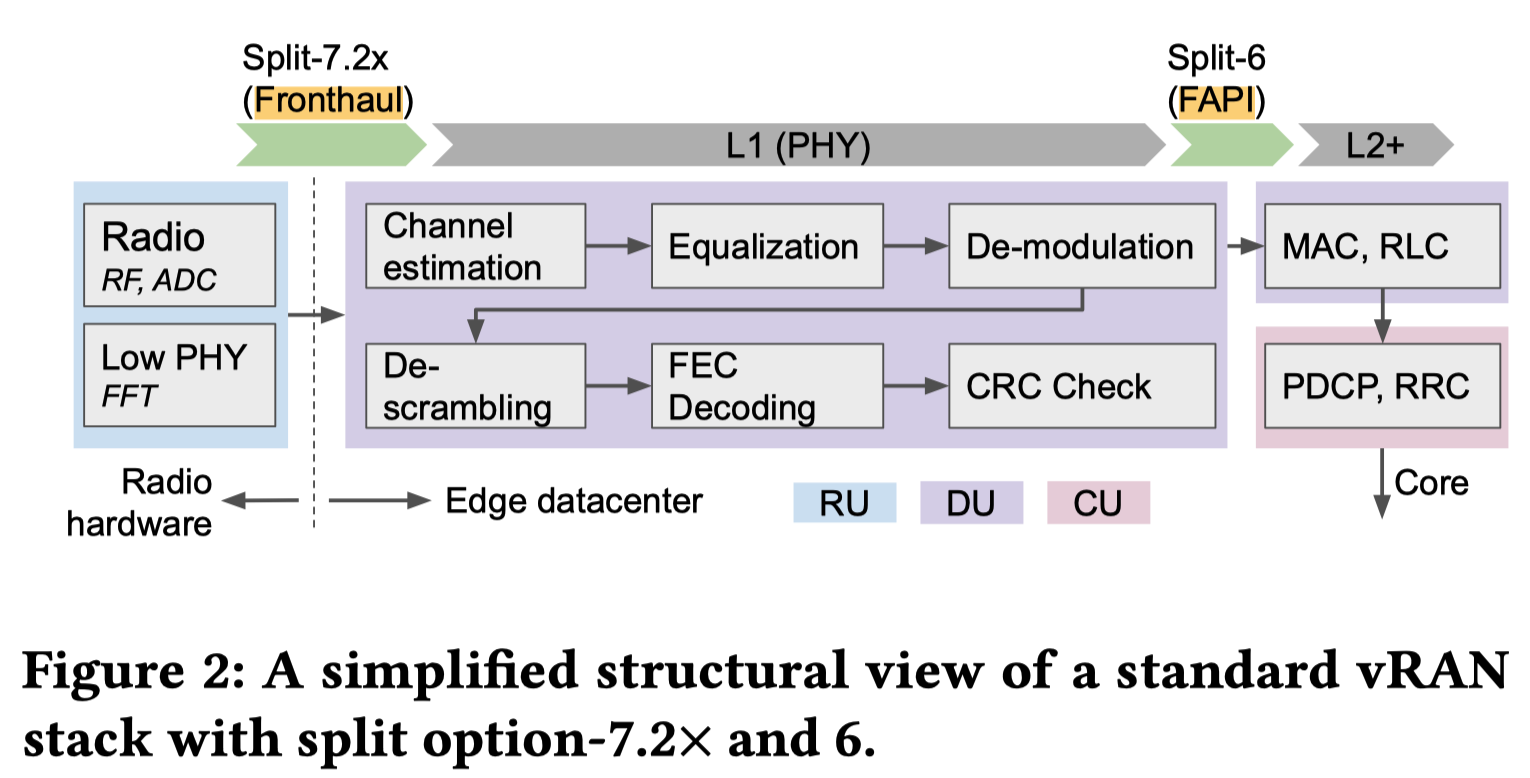
- RU与PHY之间的前传接口: 采用 O-RAN split option-7.2x 标准
- L2与PHY之间: 通过网络 FAPI 协议实现 split option-6 划分
Availability target¶
- 设定的阈值:
- Slingshot设定的目标是在发生弹性事件时,将蜂窝网络的停机时间控制在10毫秒以内
- 设定依据:
- 在常规的用户移动(越区切换/handovers)过程中,服务通常会暂停约24.7毫秒
- 将目标设定为低于越区切换的停机时间,可以确保用户设备(UE)在PHY弹性事件期间不会体验到异常的网络中断
PHY downtime with VM migration¶
-
通用迁移技术的失效:
- 由于严格的实时延迟要求,传统的虚拟机(VM)或容器迁移技术无法用于PHY弹性恢复
- 因为它们会施加高达数百毫秒的停机时间,导致UE完全断开连接
-
迁移延迟数据:
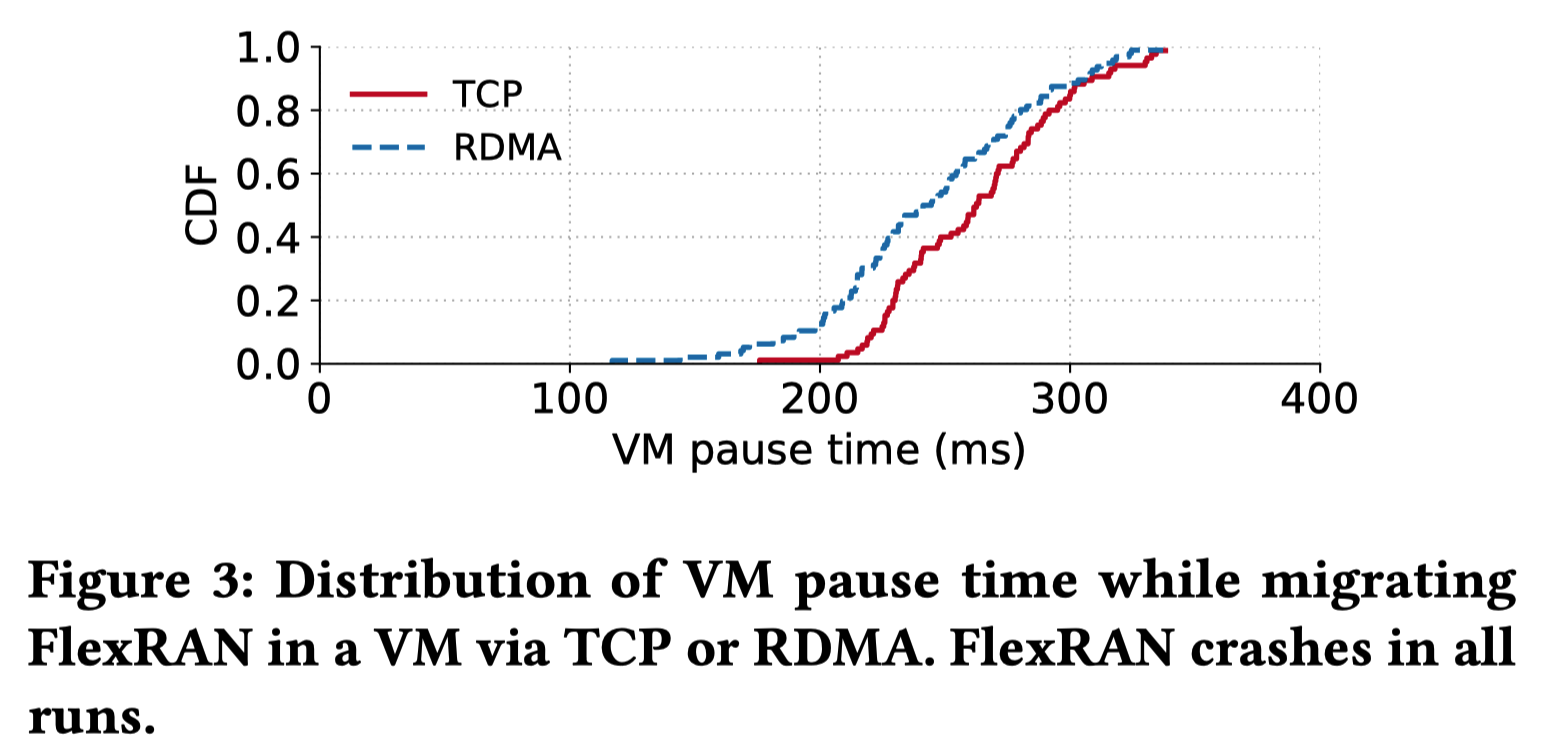
- 展示了在通过TCP或RDMA迁移运行FlexRAN的虚拟机时的暂停时间分布
- 即使进行了优化,暂停时间的中位数仍达到了244毫秒,这足以让UE完全断网
-
软件崩溃问题:
- 由于vRAN的实时层假定运行环境的抖动极低(要求线程中断时间小于10微秒),VM迁移产生的高延迟会导致FlexRAN在所有迁移运行测试中发生崩溃